

原文信息
·标 题:
An efficient memory data organization strategy for application-characteristic graph processing
·发表年份:
2022年
·原文链接:
https://journal.hep.com.cn/fcs/EN/10.1007/s11704-020-0255-y
·引用格式:
Peng FANG, Fang WANG, Zhan SHI, Dan FENG, Qianxu YI, Xianghao XU, Yongxuan ZHANG. An efficient memory data organization strategy for application-characteristic graph processing. Front. Comput. Sci., 2022, 16(1): 161607
·公众号推文链接:
01 导读
图处理因其处理现实世界中大规模和复杂的非结构化数据的能力,受到了人们的极大关注,然而,大多数图处理应用程序表现出不规则的内存访问模式,这导致内存访问流的局部性很差,缓存层次结构的次优使用可能导致CPU只在整个图处理时间的10%到45%的范围内工作。此外,各种图应用程序的运行特性存在差异,导致现有图处理框架的效率被单一的内存组织所拖累。因此,高效的内存数据组织策略是加速图处理的关键。
在目前的文献中,已有的优化内存数据组织策略在一定程度上改善了图处理过程中的局部性,但仍存在一些不足,例如,无法将内存访问模式与图的结构信息很好地结合起来;效率有限,大规模图的预处理开销很大;仅用单个内存组织数据来处理所有图形应用程序或设计一些特定的图形处理任务。
为了解决上述挑战,我们提出了一种基于应用程序运行特征的高效内存数据组织策略GMDO。具体而言,GMDO由GMDO- VR和GMDO- VI组成,分别用于遍历和迭代应用,前者采用相关度来更细粒度地组织数据,以保证遍历过程中的局部性,后者基于顶点影响加速顶点收敛,以处理迭代中的长尾分布。
02 内存数据组织策略
图通常采用压缩稀疏行(CSR)格式表示,因为其具有内存效率的优势。然而,虽然使用CSR格式可以循序访问节点的邻居列表,但进一步检索邻居的状态值将引入大量的随机内存访问,因此本文方法利用CSR作为内存格式并优化其原始内存数据组织,以此来加速图的处理。由于动态运行特性的差异,我们将图的应用分为两类:一类是遍历应用,其中包括连通分量(CC)、单源最短路径(SSSP)、广度优先搜索(BFS)等;另一类是迭代应用,其中包括标签传播算法(LPA)、网页级别(PR)、三角形计数(TC)等。CSR格式的访问模式和图形应用的分类在联机资源中给出了更多的细节。
用于遍历图应用的GMDO-VR
一般来说,公共邻点在遍历的局部性中扮演着重要的角色,因为访问具有公共邻点的顶点将有助于提高未来访问的缓存命中率。在此基础上,量化顶点之间的隐式相关性,并利用它来重组内存数据。顶点关联度R的计算公式如下:
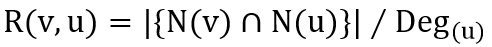
其中N(v)和N(u)表示来源顶点v和目的顶点u的相邻信息,图片为顶点u的关联度。
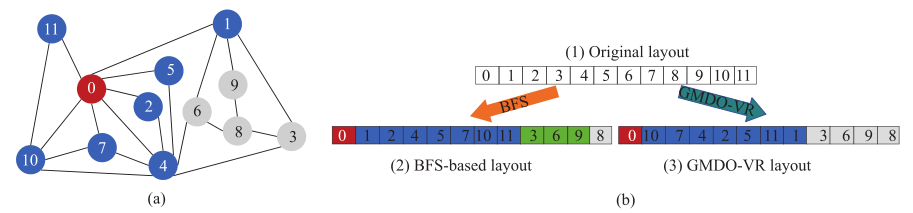
图1 GMDO-VR (a)例子;(b)不同的图数据组织
Graph G=(V,E)作为运行例如图1所示,图1(a)中有从0到11的12个顶点,图1(b)分别为原件、BFS和GMDO-VR的数据组织。如图1(b)-(2)所示,图片处理后会访问图片,但此时片上缓存中没有图片的邻点,因为图片,故需要从主存中检索数据,但这会导致计算单元等待很长时间。在这种情况下,如果考虑顶点重映射中的R,上面的情况则会有很大的不同。在图1(b)-(3)中,由于图片相较于图片的其他邻点是最高的,所以图片将与图片相邻访问,最大限度地保证遍历时的局部性。GMDO-VR算法的实现需要两个步骤,如图2所示:基于BFS遍历图结构,然后根据相关度对同一级别的顶点进行排序。GMDO-VR的时间复杂度为图片,其中图片表示顶点的平均度。
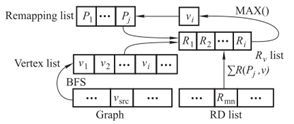
图2 GMDO-VR的实现
用于迭代图应用的GMDO-VI
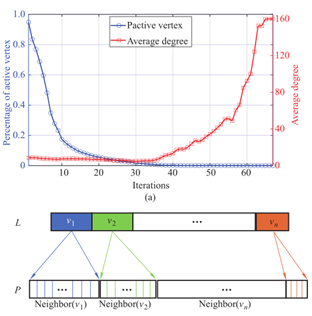
图3 (a):PageRank运行特性的变化 (b):GMDO-VI的实现
迭代应用是图应用的另一种代表类型,图3(a)显示了PageRank在web- stanford图上的运行特征。可以观察到:(1)活动顶点(PR值≥ϵ)的比值在前几次迭代中呈线性下降,但仍需要较长的时间才能达到收敛;(2)随着迭代次数的增加,平均活跃度逐渐增加,只有少数中枢顶点在处理结束时仍然活跃。直观地看,在整个执行接近尾声时参与的顶点对算法的收敛性影响较大。
从以上观察可知,在内存数据组织中应考虑图的空间格局。由于大多数真实世界的图都遵循幂律分布,故这里的顶点影响可以简单地理解为顶点度,顶点级别越大,对应用程序执行效率的影响越大。GMDO-VI的示意图模型如图3(b)所示,首先对所有顶点按顶点度降序排序,生成有序数组L,然后依次插入在L({N(v_1),N(v_2),...,N(v_n)})中顶点的相邻顶点({N(v_1),N(v_2),...,N(v_n)})到基于它们的度的重映射数组P中。这种方式将几个影响较大的顶点的邻点连续分布在缓存中,有效地满足了迭代应用的运行特性。GMDO-VI易于实现,时间复杂度为图片。
03 主要贡献
本文贡献主要如下:
1.本文探索了遍历和迭代应用程序的动态运行特性,并证明没有单一的解决方案适用于两个图域。
2.本文提出了一种高效的内存数据组织策略GMDO用于图处理,改善了局部性并且提高了CPU利用率。
3.评估结果表明,与现有的流行策略相比,GMDO能够显著提高内存访问效率,并表现出显著的性能。
04 实验结果总结
对于GMDO性能的评估,图4结果显示,GMDO在所有图上的内存访问效率一般提高了20%,甚至超过40%,更重要的是,GMDO的性能优于流行的基准测试。这表明所提出的方法可以有效地更细粒度地组织数据,确保良好的局地性,加快应用程序的性能。
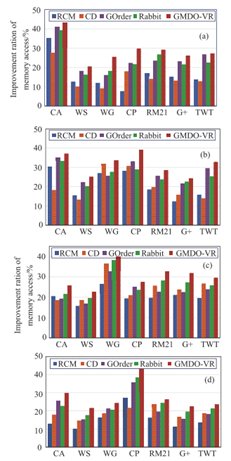
图4 RCM、CD、GOrder、Rabbit和GMDO的内存数据访问改善率
(a)CC;(b) SSSP;(C)PR;(d) LPA
对于系统加速度的计算,表1为基于GraphChi的原布局执行时间与GMDO的比值计算的系统加速度比,可以发现两种策略都将系统加速度比提高了1.50倍,甚至超过2.0倍。
表1 基于GraphChi的系统加速度比


文章中观点仅代表作者个人观点,不代表本网站的观点和看法。
神州学人杂志及神州学人网原创文章转载说明:如需转载,务必注明出处,违者本网将依法追究。






